
[My Paper Review] NeurIPS’23: Depth-discriminative Metric Learning for Monocular 3D Object Detection
Published:
[Paper link]
Our work introduces a novel metric learning scheme that boosts the performance of 3D object detection from a single 2D image, all without increasing model size or slowing down inference.
Why is Monocular 3D Object Detection Important?
3D object detection is an essential technology for autonomous cars and robots to perceive their surroundings. While expensive sensors like LiDAR or RADAR can improve accuracy, cameras are a cost-effective and easy-to-deploy solution, making them ideal for commercialization.
However, a single camera image lacks depth information, which presents a fundamental challenge for 3D object detection. In fact, multiple studies have shown that the accuracy of depth estimation has the most critical impact on overall performance compared to other factors like object size or orientation.
Motivation and Limitations of Prior Work
Previous studies often tried to improve depth prediction by adding extra modules or using additional data (like depth maps generated from LiDAR), but this increases inference time and model size.
Our research started with a simple question: “Can we make the model learn more depth-discriminative features without increasing inference time or model size?”

Our Proposed Method: Enhancing Depth with Metric Learning
We propose two “Plug-and-Play” loss functions to solve this problem. These methods can be easily added to any existing 3D object detection model to boost its performance.
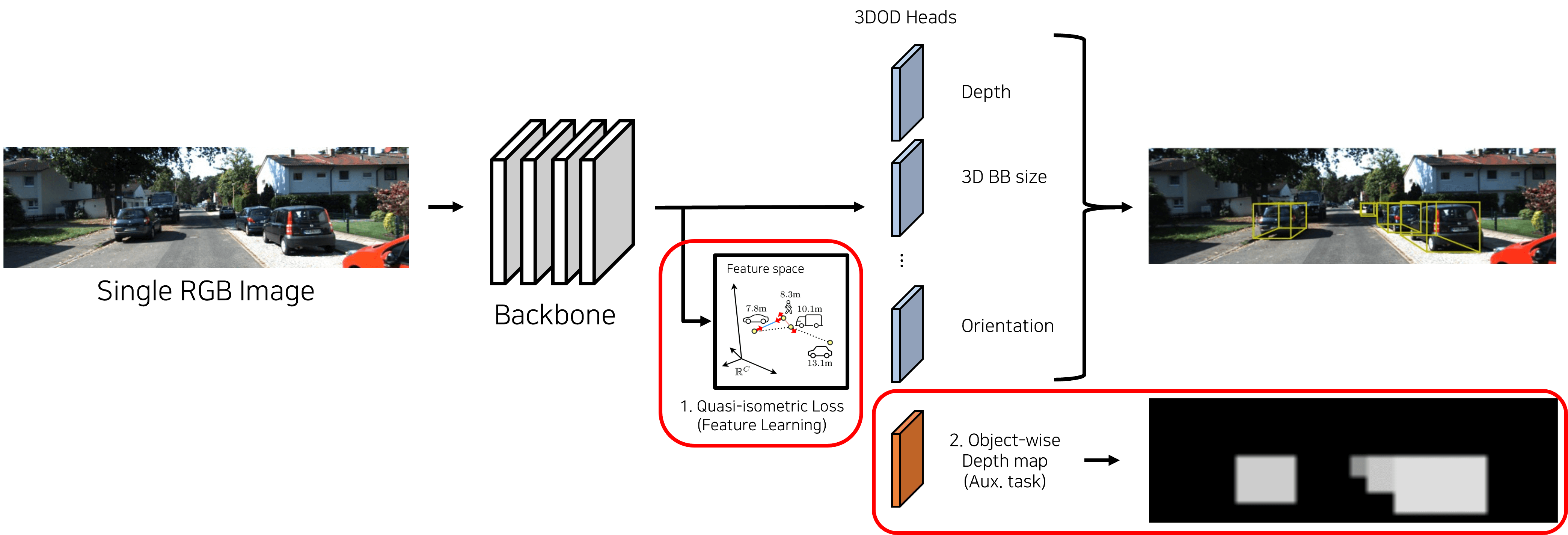
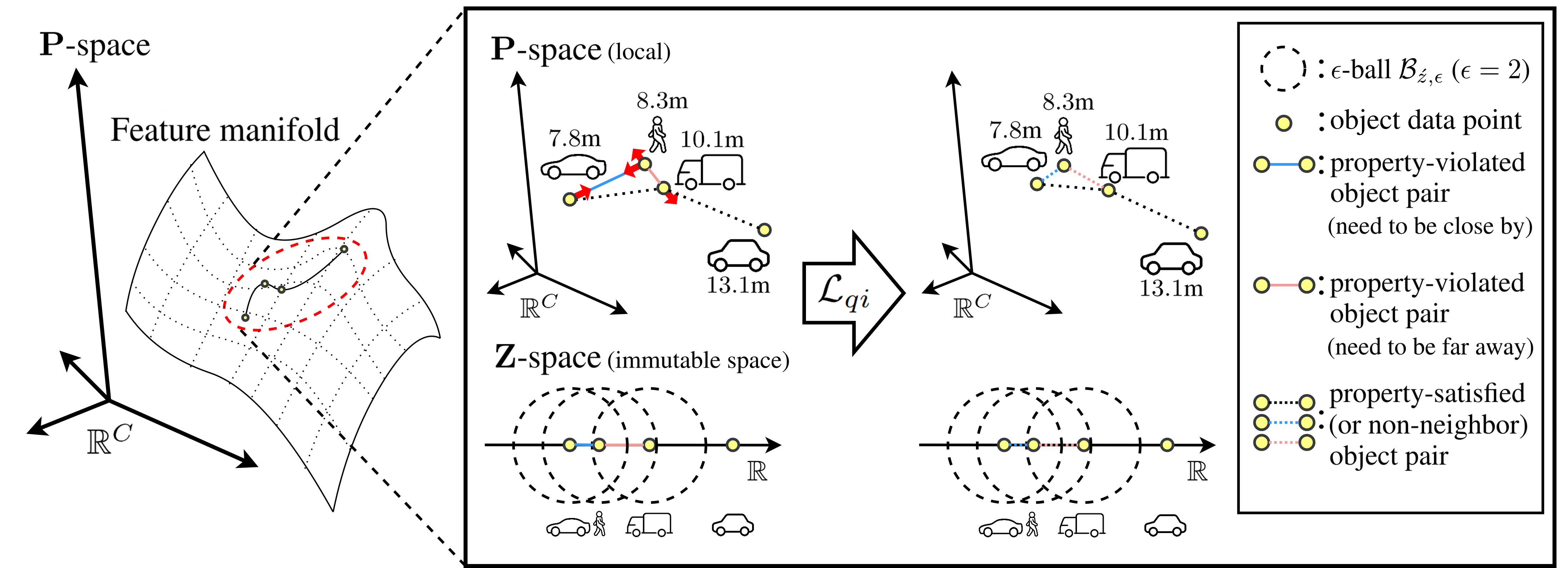
1. Quasi-isometric Loss
This is the core idea of our work. We use Metric Learning to encourage the model’s feature space to structurally resemble the real-world depth information.
- The Core Idea: We train the model so that the distance between two object features in the feature space is proportional to the difference in their real-world depth values.
- How It Works: We use a condition called
(K, B, ϵ)-quasi-isometry. This applies a flexible constraint: the distance between two features must be between (1/K) times and K times their depth difference. The model is trained by calculating a loss only for feature pairs that violate this condition. - The Advantage: This method selectively enhances depth information without disrupting the unique non-linear structure of the feature space, which is needed to learn other tasks (like object size and orientation).
2. Object-wise Depth Map Loss
Many existing models only learn the depth value at the single-pixel center of an object. This can lead to large depth errors if the center prediction is slightly off during inference.
To mitigate this, we introduced an auxiliary task that predicts and learns depth values over the entire 2D bounding box of an object. This auxiliary head is used only during training and is removed during inference, so there is no increase in inference time.
Experimental Results: Outstanding Performance Gains
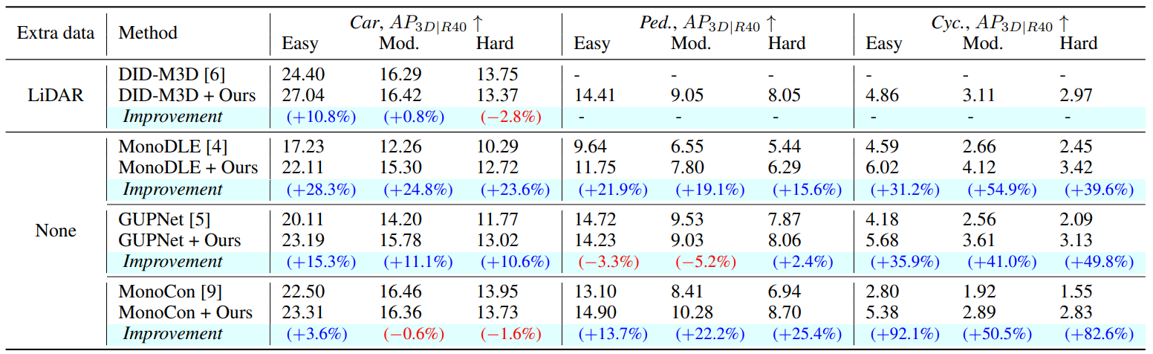
When we applied our method to several state-of-the-art 3D object detection models (DID-M3D, MonoDLE, GUPNet, MonoCon), we confirmed significant performance improvements across the board without any increase in inference time.
- On the KITTI Dataset: On average, we saw an overall performance (AP) improvement of 10.3% for Cars, 12.4% for Pedestrians, and 53.1% for Cyclists. The performance gain was even more pronounced for models trained without extra data.
- On the Waymo Dataset: Our method also proved its generality on the larger and more complex Waymo dataset, achieving an average performance increase of over 4.5% across all metrics and conditions.
The image below shows a qualitative comparison between a baseline model (blue boxes) and our model (red boxes). You can see that our predictions align much more closely with the ground truth (green boxes).
Conclusion
In this work, we proposed a novel metric-learning-based loss function that significantly improves the depth estimation capabilities of monocular 3D object detection models without adding any inference overhead. Because our “plug-and-play” method can be easily applied to various frameworks, we expect it to contribute to enhancing the 3D detection performance of products that use edge devices in the future.
Thanks for reading! If you have any questions, feel free to ask in the comments.